
Google Analytics 4 offers a wealth of information that is very useful to marketing analysts. However, they cannot access the data efficiently because the GA4 BigQuery Data Exports do not have scheduled or guaranteed times they are made available, it can happen at any time, creating uncertainty for those relying on the data for timely analysis.
In this article, we will discuss a simple way to build a solution that will be able to retrieve the data from GA4 BigQuery Data Exports as soon as they are available, and support near real-time reporting for your GA4 Analytics Dashboards to make timely, data-driven decisions.
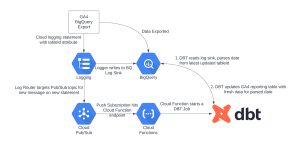
Create an Event-Driven Data Ingestion Pipeline
The first step in building a solution to retrieve data in a timely manner is to stack a few Google Cloud Platform (GCP) services together to achieve an event-driven data ingestion pipeline for GA4 BigQuery exports.
At a high level, the following services make up the components of this pipeline:
Cloud Logging
For this component, one log sink and two routers are set up. The log sink captures logging outputs from the GA4 Data Export Jobs, and the routers take record of the output in BigQuery, and notify a Pub/Sub topic respectively.
Pub/Sub
A topic sits behind the logging route in order to receive the messages as GA4 Export Jobs run throughout the day. The subscription underneath the topic pushes each message to a Cloud Function endpoint and acknowledges each message when processed.
Cloud Functions
A pivotal part of the pipeline involves a single cloud function tasked with two major responsibilities: initiating a DBT Job Run and verifying the outcome of this run, determining whether it was successful or not.
BigQuery
This essential component includes a table specifically for the logging data captured by the log sink, and two datasets: one for the raw GA4 exported data, and another for the downstream reporting tables.
Cloud DBT
Capping the end of the data pipeline, DBT Jobs are defined in order to orchestrate your pipeline and ensure that the data flows exactly as you need. Alternatively, a simpler solution like BigQuery Scheduled Queries can achieve a similar result.
Set Up Log Sinks and Routers Inside Cloud Logging
Cloud Logging serves two purposes:
- To create a log sink with a filter to export all GA4-related messaging to the sink in BigQuery
- To create a log router with the same filter as above, to create a new Pub/Sub topic and send messages each time it is logged that data has been exported by GA4.
The filter below is designed to filter only for messages where GA4 has exported new data.

It’s important to establish these two resources early in the process to enhance efficiency when running queries to update the reporting tables. The DBT job runs after the Pub/Sub subscription pushes a request to the endpoint, so the DBT model can pick up the latest log message and parse the date and filter the raw GA4 tables based on that date.
Since the raw data is already sharded into separate tables by day, it raises the question: “Why not just use the table ID and query from that exact table?” This approach is not optimal as it requires constant updates to the DBT project with each individually sharded table as it becomes available, which is time-consuming and inefficient. A more efficient and effective method is to leverage the wildcard query to define the GA4 dataset as the source, then filter by date.
Create Your Topics and Subscriptions Within Cloud Pub/Sub
In Pub/Sub, a topic is created to target the Cloud Logging router, using the specified filter above – this topic will only send messages whenever GA4 exports data. Once the topic is created, it’s necessary to return to the Pub/Sub topic to establish the subscription. The subscription will push to the Cloud Function endpoint, which in turn triggers the DBT job. Message filtering is not required in this step, as it was already addressed during the creation of the Cloud Logging router, so no additional filtering is required.
Deploy the Code to Cloud Functions
The Cloud Function depends on a few things to be fully functional. It requires configuring a scheduled query or the DBT job to run either resource once the Pub/Sub subscription acknowledges and pushes the message to the endpoint. The Cloud Function should be implemented after your scheduled query is ready and configured, and before you set up the Pub/Sub subscription, because this subscription relies on the Cloud Function Trigger URL.
Set Up Models in DBT
There’s a neat trick for querying the raw GA4 data in DBT, utilizing the dbt–utils package and the jinja-templated macro functionality that makes DBT so powerful. Essentially, before showing the code snippet, query the log sink that is set up in BigQuery to retrieve the most recent record, ordered by the log statement’s timestamp. Then, the ‘tableId’ field is extracted, and string manipulation in python is used to extract the date from the Table ID field.
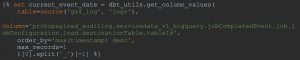
With current_event_date set now we can filter on the GA4 data such as:

When dealing with the raw GA4 dataset, it’s very important to filter either the date field or specify which sharded tables to query from, otherwise your queries can get very expensive.
Watch the Data Flow In
With these GCP services and techniques implemented, sit back and watch your data flow seamlessly into your custom-built Google Analytics 4 reporting tables. And if you visualized a dashboard on top of the table, you’ll be able to see the visuals update in real-time. While the availability of GA4 BigQuery Data Exports can be a problem, the solution outlined above offers a way to access the data in a timely manner. With this method, marketing analysts can ensure near real-time reporting, harnessing the full potential of GA4 data for insightful analysis and strategic actions.